Capítulo 38 Organizando con Unix
Unix es el sistema operativo de elección en el campo de ciencia de datos. Le presentaremos la forma de pensar de Unix utilizando un ejemplo: cómo mantener organizado un proyecto de análisis de datos. Aprenderemos algunos de los comandos más utilizados a lo largo del camino. Sin embargo, no entraremos en detalles aquí. Les recomendamos que aprendan más, especialmente cuando se encuentran usando demasiado el mouse o realizando una tarea repetitiva con frecuencia. En esos casos, probablemente hay una forma más eficiente de hacerlo en Unix. Aquí tenemos algunos cursos básicos para comenzar:
- https://www.codecademy.com/learn/learn-the-command-line
- https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-1
- https://www.coursera.org/learn/unix
También hay muchos libros de referencia125. Por ejemplo, Bite Size Linux126 y Bite Size Command Line127 son particularmente claros, concisos y completos.
Cuando busquen recursos de Unix, recuerden que otros términos utilizados para describir lo que aprenderemos aquí son Linux, el shell y la línea de comando. Básicamente, lo que estamos aprendiendo es una serie de comandos y una forma de pensar que facilita la organización de los archivos sin usar el mouse.
Como motivación, vamos a comenzar construyendo un directorio utilizando herramientas de Unix y RStudio.
38.1 Convención de nomenclatura
Antes de comenzar a organizar proyectos con Unix, deben elegir una convención que usarán para sistemáticamente nombrar sus archivos y directorios. Esto les ayudará a encontrar archivos y saber qué hay en ellos.
En general, quieren nombrar sus archivos de una manera que se relaciona con sus contenidos y que especifica cómo se relacionan con otros archivos. El Smithsonian Data Management Best Practices128 ofrece “cinco preceptos para el nombramiento y la organización de archivos”. Estos son:
- Tener un nombre distintivo, legible por humanos que indique el contenido.
- Seguir un patrón consistente que sea conveniente para la automatización.
- Organizar los archivos en directorios (cuando sea necesario) que siguen un patrón consistente.
- Evitar la repetición de elementos semánticos en los nombres de los archivos y directorios.
- Tener una extensión de archivo que coincida con el formato del archivo (¡sin cambiar las extensiones!)
Para recomendaciones específicas, pueden consultar The Tidyverse Style Guide129.
38.2 El terminal
En lugar de hacer clic, arrastrar y soltar para organizar nuestros archivos y carpetas, escribiremos comandos de Unix en el terminal. La forma en que hacemos esto es similar a cómo escribimos comandos en la consola R, pero en lugar de generar gráficos y resúmenes estadísticos, organizaremos archivos en nuestro sistema.
Necesitarán acceso a un terminal130. Una vez que tengan un terminal abierto, pueden comenzar a escribir comandos. Deberían ver un cursor intermitente en el lugar donde se muestra lo que escriben. Esta posición se llama la línea de comando (command line en inglés). Una vez que escriban algo y presionen enter en Windows o return en la Mac, Unix intentará ejecutar este comando. Si quieren intentar un ejemplo, escriban lo siguiente en su línea de comando:
echo "hello world"El comando echo es parecido a cat en R. Al ejecutar esta línea deberían ver hello world y entonces vuelven a la línea de comando.
Tengan en cuenta que no pueden usar el mouse para moverse en el terminal. Tienen que usar el teclado. Para volver a un comando que escribieron anteriormente, pueden usar la flecha hacia arriba.
Noten que anteriormente incluimos un fragmento de código que muestra los comandos de Unix de la misma manera que anteriormente mostramos los comandos R. Nos aseguraremos de distinguir cuándo el comando está destinado a R y cuándo está destinado a Unix.
38.3 El sistema de archivos
Nos referimos a todos los archivos, carpetas y programas en su computadora como el sistema de archivos (filesystem en inglés). Recuerden que las carpetas y los programas también son archivos, pero este es un tecnicismo en que rara vez pensamos e ignoraremos en este libro. Nos enfocaremos en los archivos y las carpetas por el momento y discutiremos los programas, o ejecutables, en una sección posterior.
38.3.1 Directorios y subdirectorios
El primer concepto que necesitan entender para convertirse en un usuario de Unix es cómo está organizado su sistema de archivos. Deberían considerarlo como una serie de carpetas anidadas, cada una con archivos, carpetas y ejecutables.
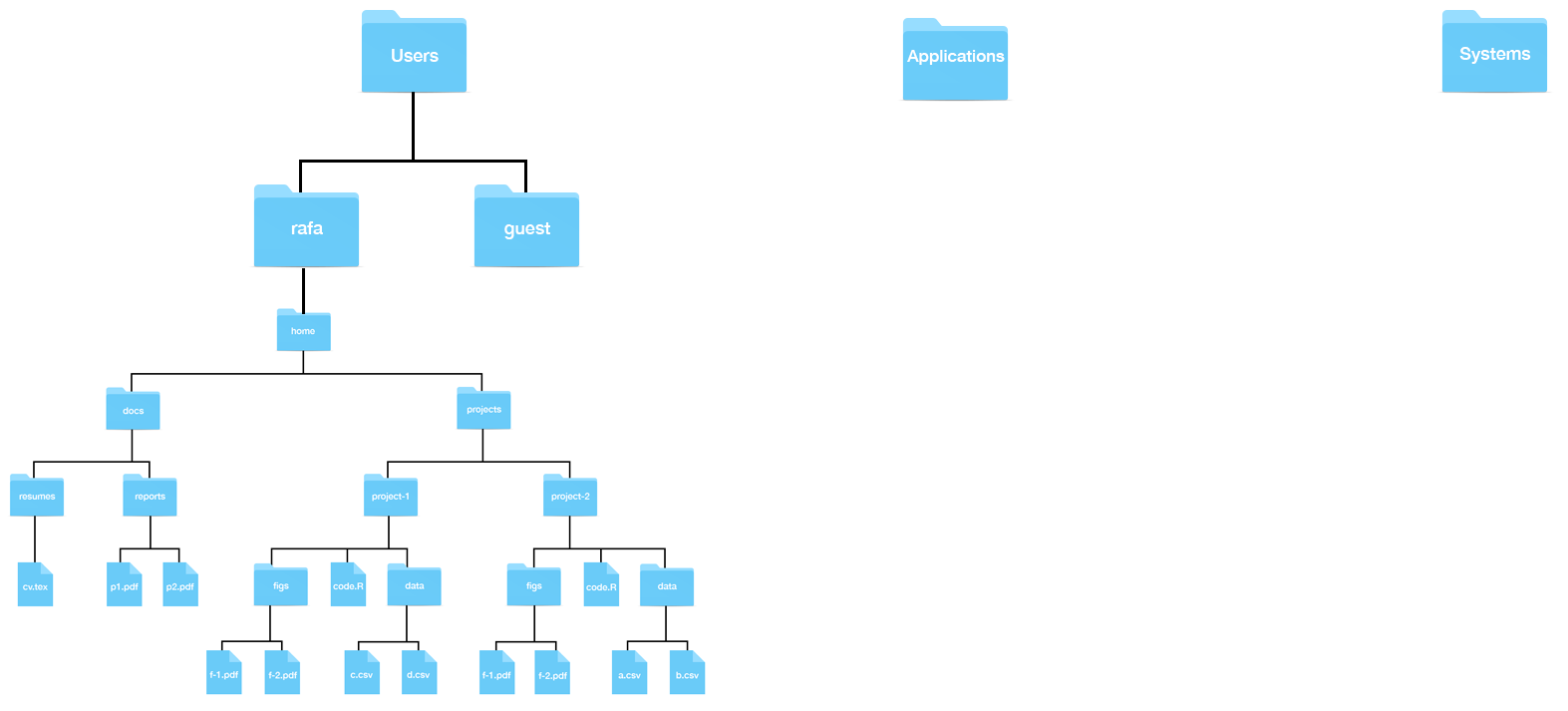
Aquí hay una representación visual de la estructura que estamos describiendo:
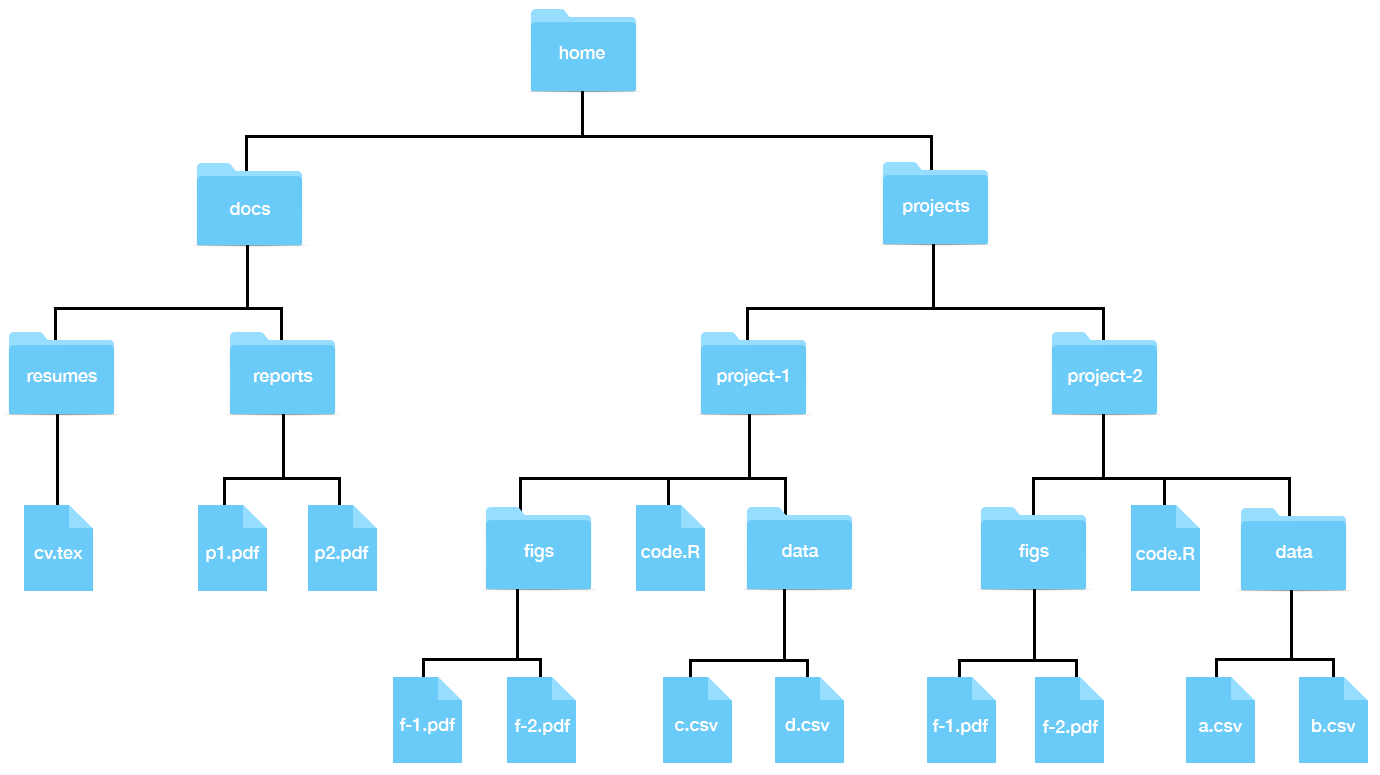
En Unix, nos referimos a las carpetas como directorios. Los directorios que están dentro de otros directorios a menudo se denominan subdirectorios. Entonces, por ejemplo, en la figura anterior, el directorio docs tiene dos subdirectorios: reports y resumes, y docs es un subdirectorio de home.
38.3.2 El directorio home
El directorio home es donde se guardan todas sus cosas, a diferencia de los archivos del sistema que vienen con sus computadoras, que se guardan en otro lugar. En la figura anterior, el directorio denominado “home” representa su directorio home, pero raras veces se llama así. En sus sistemas, el nombre de su directorio home probablemente será el mismo que su nombre de usuario en ese sistema. A continuación vemos un ejemplo en Windows y Mac que muestra un directorio home, en este caso, llamado rafa:
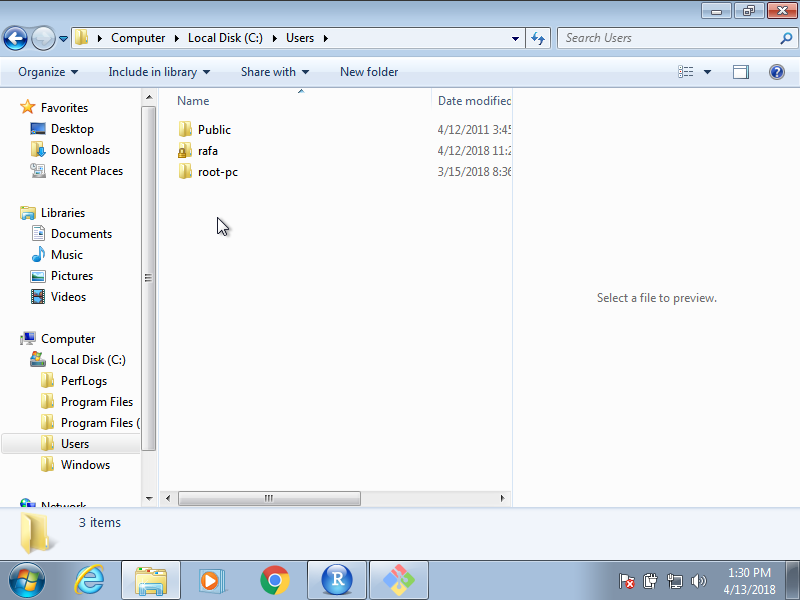
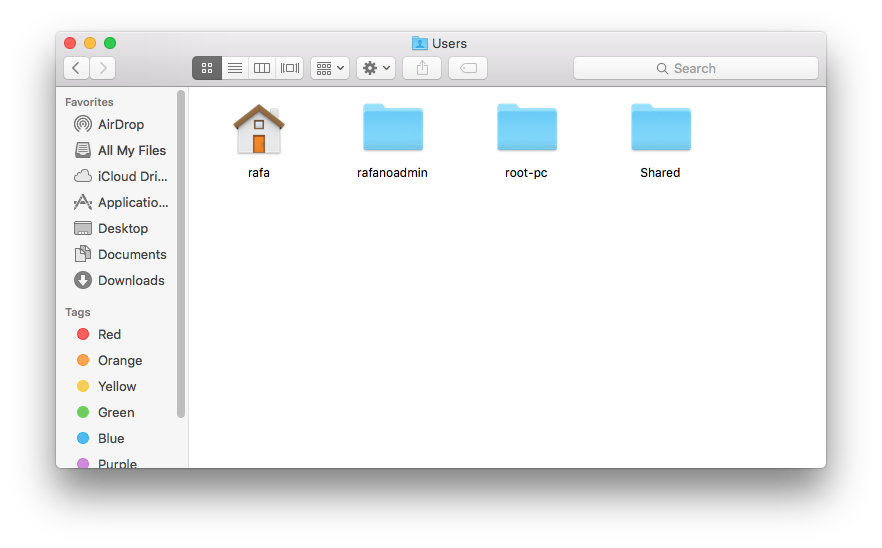
Ahora, miren a la figura anterior que muestra un sistema de archivos. Supongan que están utilizando un sistema de apuntar y hacer clic y desea eliminar el archivo cv.tex. Imaginen que en su pantalla pueden ver el directorio home. Para borrar este archivo, deben hacer doble clic en el directorio home, luego docs, entonces resumes y luego arrastrar cv.tex a la basura. Aquí están experimentando la naturaleza jerárquica del sistema: cv.tex es un archivo dentro del directorio resumes, que es un subdirectorio dentro del directorio docs, que es un subdirectorio del directorio home.
Ahora supongan que no pueden ver su directorio home en su pantalla. De alguna manera, deberían hacer que aparezca en su pantalla. Una forma de hacerlo es navegar desde lo que se llama el directorio raíz (root directory en inglés) hasta el directorio home. Cualquier sistema de archivos tendrá lo que se llama un directorio raíz, que es el directorio que contiene todos los directorios. El directorio home, que se muestra en la figura anterior, generalmente estará a dos o más niveles del directorio raíz. En Windows, tendrán una estructura como esta:
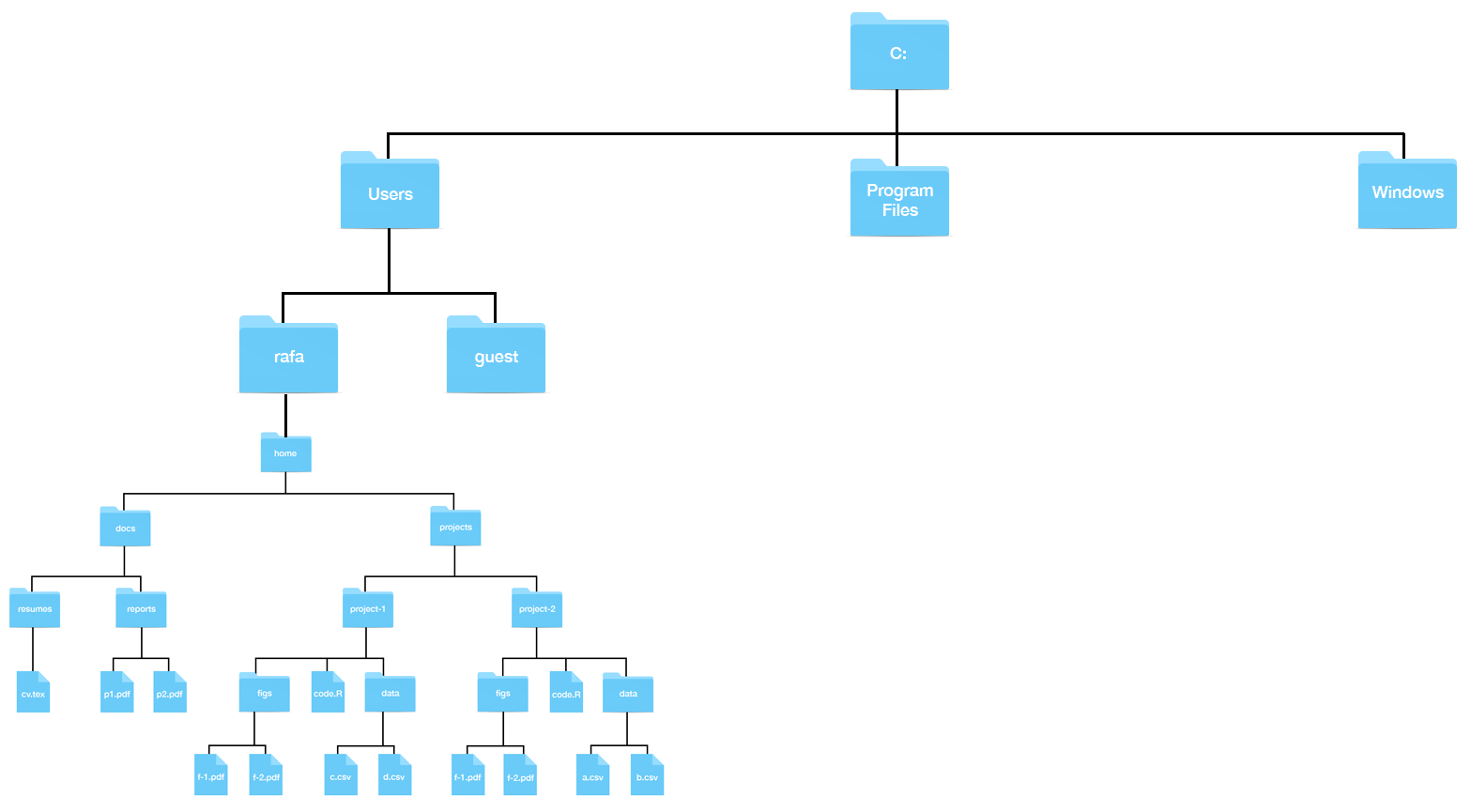
mientras en la Mac, será así:
Nota para usuarios de Windows: La instalación típica de R hará que su directorio Documents sea su directorio home en R. Esto probablemente será diferente de su directorio home en Git Bash. En general, cuando discutimos directorios home, nos referimos al directorio home de Unix que para Windows, en este libro, es el directorio de Git Bash Unix.
38.3.3 Directorio de trabajo
El concepto de una ubicación actual (current location en inglés) es parte de la experiencia de apuntar y hacer clic: en cualquier momento estamos en una carpeta y vemos el contenido de esa carpeta. A medida que busquen un archivo, como lo hicimos anteriormente, experimentarán el concepto de una ubicación actual: una vez que hagan doble clic en un directorio, cambiarán de ubicación y estarán en esa carpeta, a diferencia de la carpeta en la que estaban antes.
En Unix, no tenemos las mismas señales visuales, pero el concepto de una ubicación actual es indispensable. Nos referimos a esto como el directorio de trabajo (working directory en inglés). Cada ventana del terminal que tienen abierta tiene un directorio de trabajo asociado.
¿Cómo sabemos cuál es nuestro directorio de trabajo? Para responder a esto, aprendemos nuestro primer comando de Unix: pwd, que significa imprimir el directorio de trabajo (print working directory en inglés). Este comando devuelve el directorio de trabajo.
Abran un terminal y escriban:
pwdNo mostramos el resultado de ejecutar este comando porque será muy diferente en sus sistemas en comparación con otros. Si abren un terminal y escriben pwd como su primer comando, deberían ver algo como /Users/yourusername en la Mac o algo como /c/Users/yourusername en Windows. La cadena de caracteres devuelta al llamar pwd representa su directorio de trabajo. Cuando abrimos un terminal por primera vez, empezamos en nuestro directorio home, por lo que en este caso el directorio de trabajo es el directorio home.
Tengan en cuenta que las barras diagonales / en las cadenas de arriba separan los directorios. Entonces, por ejemplo, la ubicación /c/Users/rafa implica que nuestro directorio de trabajo se llama rafa y es un subdirectorio de Users, que es un subdirectorio de c, que es un subdirectorio del directorio raíz. Por lo tanto, el directorio raíz está representado solo por una barra diagonal: /.
38.3.4 Rutas
Nos referimos a la cadena devuelta por pwd como la ruta completa (full path en inglés) del directorio de trabajo. El nombre proviene del hecho de que esta cadena explica la ruta que deben seguir para llegar al directorio en cuestión desde el directorio raíz. Cada directorio tiene una ruta completa. Más adelante, aprenderemos sobre rutas relativas, que nos dicen cómo llegar a un directorio desde el directorio de trabajo.
En Unix, usamos la abreviatura ~ para representar su directorio home. Entonces, por ejemplo, si docs es un directorio en su directorio home, la ruta completa para docs puede escribirse así ~/docs.
La mayoría de los terminales mostrarán la ruta de su directorio de trabajo directamente en la línea de comando. Si están utilizando la configuración predeterminada y abren un terminal en la Mac, verán que justo en la línea de comando tienen algo como computername:~ username con ~ representando su directorio de trabajo, que en este ejemplo es el directorio home ~. Lo mismo es cierto para el terminal Git Bash, donde verán algo como username@computername MINGW64 ~, con el directorio de trabajo al final. Cuando cambiemos los directorios, veremos este cambio tanto en Macs como en Windows.
38.4 Comandos de Unix
Ahora aprenderemos una serie de comandos de Unix que nos permitirán preparar un directorio para un proyecto de ciencia de datos. También ofrecemos ejemplos de comandos que, si escriben en su terminal, devolverán un error. Esto es porque suponemos que tenemos el sistema de archivos mostrado en el diagrama anterior. Su sistema de archivos es diferente. En la siguiente sección, le ofreceremos ejemplos que pueden escribir.
38.4.1 ls: Listado de contenido del directorio
En un sistema de apuntar y hacer clic, sabemos lo que hay en un directorio porque lo vemos. En el terminal, no vemos los íconos. En cambio, usamos el comando ls para enumerar el contenido del directorio.
Para ver el contenido de su directorio personal, abran un terminal y escriban:
lsVeremos más ejemplos pronto.
38.4.2 mkdir y rmdir: crear y eliminar un directorio
Cuando nos estamos preparando para un proyecto de ciencia de datos, necesitaremos crear directorios. En Unix, podemos hacer esto con el comando mkdir, que significa crear directorio (make directory en inglés).
Debido a que pronto estarán trabajando en varios proyectos, les recomendamos crear un directorio llamado proyectos en su directorio home.
Pueden intentar este ejemplo en su sistema. Abran un terminal y escriban:
mkdir projectsSi hacen esto correctamente, no pasará nada: no tener noticias es buena noticia. Si el directorio ya existe, recibirán un mensaje de error y el directorio existente permanecerá intacto.
Para confirmar que crearon este directorio, pueden verlo usando:
lsVerán una lista de cualquier directorio o archivo, incluyendo los que acaban de crear.
Con fines ilustrativos, vamos a crear algunos directorios más. Pueden enumerar más de un nombre de directorio así:
mkdir docs teachingPueden verificar si se crearon los tres directorios:
lsSi cometieron un error y necesitan eliminar un directorio, pueden usar el comando rmdir (remove directory en inglés):
mkdir junk
rmdir junkEsto eliminará el directorio siempre y cuando esté vacío. Si no está vacío, recibirán un mensaje de error y el directorio permanecerá intacto. Para eliminar directorios que no están vacíos, más tarde aprenderemos sobre el comando rm.
38.5 Algunos ejemplos
Exploremos algunos ejemplos de como usar cd. Para ayudarles visualizar, mostraremos la representación gráfica de nuestro sistema de archivos verticalmente:
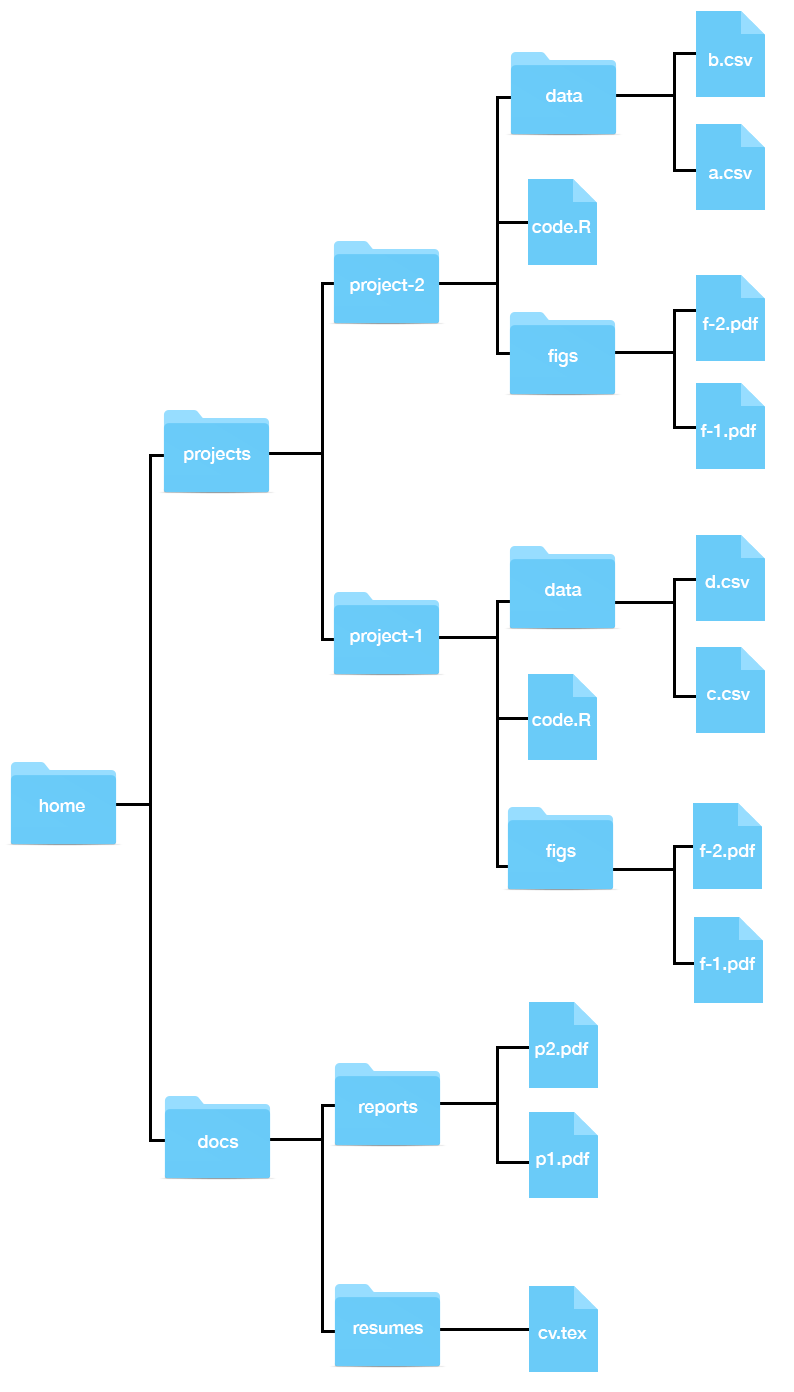
Supongan que nuestro directorio de trabajo es ~/projects y queremos mover figs a project-1.
En este caso, es conveniente usar rutas relativas:
cd project-1/figsAhora supongan que nuestro directorio de trabajo es ~/projects y queremos mover reports a docs, ¿cómo podemos hacer esto?
Una forma es usar rutas relativas:
cd ../docs/reportsOtra es usar la ruta completa:
cd ~/docs/reportsSi están intentando esto en su sistema, recuerden aprovecharse de que Unix autocompleta.
Examinemos un ejemplo más. Supongan que estamos en ~/projects/project-1/figs y queremos cambiar a ~/projects/project-2. De nuevo, hay dos formas.
Con rutas relativas:
cd ../../proejct-2y con rutas completas:
cd ~/projects/project-238.6 Más comandos de Unix
38.6.1 mv: mover archivos
En un sistema de apuntar y hacer clic, movemos los archivos de un directorio a otro arrastrando y soltando. En Unix, usamos el comando mv.
Advertencia: mv no les preguntará “¿estás seguro?” si su cambio resulta en sobrescribir un archivo.
Ahora que saben cómo usar rutas completas y relativas, usar mv es relativamente sencillo. La forma general es:
mv path-to-file path-to-destination-directoryPor ejemplo, si queremos mover el archivo cv.tex desde resumes a reports, podrían usar las rutas completas de esta manera:
mv ~/docs/resumes/cv.tex ~/docs/reports/También pueden usar rutas relativas y hacer lo siguiente:
cd ~/docs/resumes
mv cv.tex ../reports/o esto:
cd ~/docs/reports/
mv ../resumes/cv.tex ./Observen que en el último usamos el acceso directo al directorio de trabajo . para dar una ruta relativa como el directorio de destino.
También podemos usar mv para cambiar el nombre de un archivo. Para hacer esto, en lugar de que el segundo argumento sea el directorio de destino, también incluye un nombre de archivo. Entonces, por ejemplo, para cambiar el nombre de cv.tex a resume.tex, simplemente escribimos:
cd ~/docs/resumes
mv cv.tex resume.texTambién podemos combinar el movimiento y un cambio de nombre. Por ejemplo:
cd ~/docs/resumes
mv cv.tex ../reports/resume.texY podemos mover directorios completos. Para mover el directorio resumes a reports, hacemos lo siguiente:
mv ~/docs/resumes ~/docs/reports/Es importante agregar el último / para que quede claro que no desean cambiar el nombre del directorio resumes a reports, sino más bien moverlo al directorio reports.
38.6.2 cp: copiando archivos
El comando cp se comporta de manera similar a mv excepto que en lugar de mover, copiamos el archivo, que significa que el archivo original permanece intacto.
Entonces, en todos los ejemplos mv anteriores, pueden cambiar mv a cp y copiarán en lugar de mover con una excepción: no podemos copiar directorios completos sin aprender sobre argumentos, que haremos más adelante.
38.6.3 rm: eliminar archivos
En los sistemas de apuntar y hacer clic, eliminamos los archivos arrastrándolos y soltándolos en la basura o haciendo un clic especial con el mouse. En Unix, usamos el comando rm.
Advertencia: A diferencia de echar archivos a la basura, rm es permanente ¡Tengan cuidado!
La forma general en que funciona es la siguiente:
rm filenameDe hecho, pueden enumerar archivos así:
rm filename-1 filename-2 filename-3Pueden usar rutas completas o relativas. Para eliminar directorios, tendrán que aprender sobre argumentos, que haremos más adelante.
38.6.4 less: mirando un archivo
A menudo, desearán ver rápidamente el contenido de un archivo. Si tal archivo es un archivo de texto, la forma más rápida de hacerlo es mediante el comando less. Para ver el archivo cv.tex, deben hacer lo siguiente:
cd ~/docs/resumes
less cv.texPara escapar del visualizador, escriban q. Si los archivos son largos, pueden usar las teclas de flecha para moverse hacia arriba y hacia abajo. Hay muchos otros comandos de teclado que pueden usar dentro de less para, por ejemplo, buscar o saltar páginas. Aprenderán más sobre esto en una sección posterior. Si se preguntan por qué se llama el comando less, es porque el original fue llamado more, como en “show me more of this file” o “muéstrame más de este archivo”. La segunda versión se llamó less por el dicho “less is more” o “menos es más”.
38.7 Preparación para un proyecto de ciencia de datos
Ahora estamos listos para preparar un directorio para un proyecto. Utilizaremos el proyecto de asesinatos de Estados Unidos131 como ejemplo.
Deberían comenzar creando un directorio donde guardarán todos sus proyectos. Recomendamos un directorio llamado projects en su directorio home. Para hacer esto, escriban:
cd ~
mkdir projectsNuestro proyecto se relaciona con asesinatos por armas de fuego, por lo que llamaremos al directorio de nuestro proyecto: murders. Será un subdirectorio en nuestro directorio de proyecto. En el directorio murders, crearemos dos subdirectorios para contener los datos sin procesar y los datos intermedios. Llamaremos a estos data y rda, respectivamente.
Abran un terminal y asegúrense de estar en el directorio home:
cd ~Ahora ejecuten los siguientes comandos para crear la estructura de directorio que queremos. Al final, usamos ls y pwd para confirmar que hemos generado el directorio correcto en el directorio de trabajo correcto:
cd projects
mkdir murders
cd murders
mkdir data rdas
ls
pwdTengan en cuenta que la ruta completa de nuestro set de datos murders es ~/projects/murders.
Entonces, si abrimos un nuevo terminal y queremos navegar en ese directorio, escribimos:
cd projects/murdersEn la Sección 40.3, describiremos cómo podemos usar RStudio para organizar un proyecto de análisis de datos, una vez que se hayan creado este directorio.
38.8 Unix avanzado
La mayoría de las implementaciones de Unix incluyen una gran cantidad de herramientas y utilidades eficaces. Acabamos de aprender los conceptos básicos. Recomendamos que utilicen Unix como su herramienta principal de administración de archivos. Tomará tiempo sentirse cómodo con él, pero durante este tiempo, aprenderán mucho buscando soluciones en el Internet. En esta sección, superficialmente cubrimos temas ligeramente más avanzados. El objetivo principal de la sección es informarles sobre lo que está disponible en lugar de explicar todo en detalle.
38.8.1 Argumentos
La mayoría de los comandos de Unix se pueden ejecutar con argumentos. Los argumentos generalmente se definen usando un guión - o dos guiones -- (según el comando) seguido de una letra o una palabra. Un ejemplo de un argumento es una -r detrás rm. La r significa recursivo y el resultado es que los archivos y directorios se eliminan recursivamente. O sea, si escriben:
rm -r directory-namese eliminarán todos los archivos, subdirectorios, archivos en subdirectorios, subdirectorios en subdirectorios, etc. Esto es equivalente a echar una carpeta en la basura, excepto que no pueden recuperarla. Una vez que la eliminen, se eliminará para siempre. Frecuentemente, cuando eliminan directorios, encontrarán archivos que están protegidos. En tales casos, pueden usar el argumento -f que significa force.
También pueden combinar argumentos. Por ejemplo, para eliminar un directorio independientemente de los archivos protegidos, escribirían:
rm -rf directory-nameRecuerden que una vez que eliminen no hay marcha atrás. Por lo tanto, deben usar este comando con mucho cuidado.
Un comando que a menudo se llama con argumentos es ls. Aquí hay un ejemplo:
ls -aLa a representa a “todos” (all en inglés). Este argumento hace que ls les muestre todos los archivos en el directorio, incluyendo los archivos ocultos. En Unix, todos los archivos que comienzan con un . están escondidos. Muchas aplicaciones crean directorios ocultos para almacenar información importante sin interferir con su trabajo. Un ejemplo es git (que discutimos en detalle más adelante). Una vez que inicializen un directorio como un directorio git con git init, se crea un directorio oculto llamado .git. Otro archivo oculto es el archivo .gitignore.
Otro ejemplo de usar un argumento es:
ls -lLa l significa “largo” y el resultado es que se muestra más información sobre los archivos.
A menudo es útil ver los archivos en orden cronológico. Para eso usamos:
ls -ty para invertir (reverse en inglés) el orden de cómo se muestran los archivos, pueden usar:
ls -rPodemos combinar todos estos argumentos para mostrar más información para todos los archivos en orden cronológico inverso:
ls -lartCada comando tiene un conjunto diferente de argumentos. En la siguiente sección, aprendemos cómo averiguar qué hacen cada uno.
38.8.2 Obtener ayuda
Como habrán notado, Unix usa una versión extrema de abreviaturas. Esto lo hace muy eficiente, pero también difícil de adivinar cómo llamar a los comandos. Para compensar por esta debilidad, Unix incluye archivos de ayuda completos o man pages (“man” es la abreviatura de manual). En la mayoría de los sistemas, pueden escribir man, seguido por el nombre del comando para obtener ayuda. Entonces para ls, escribiríamos:
man lsEste comando no está disponible en algunas de las implementaciones compactas de Unix, como Git Bash. Una forma alternativa de obtener ayuda que funciona en Git Bash es escribir el comando seguido de --help. Entonces para ls, sería lo siguiente:
ls --help38.8.3 El pipe
Las páginas de ayuda suelen ser largas y si escriben los comandos que hemos discutido, enseña todo el documento. Sería útil si pudiéramos guardar el manual en un archivo y luego usar less para verlo. El pipe, escrito así |, hace algo parecido. Transmite los resultados de un comando al comando después de pipe. Esto es similar al pipe |> que usamos en R. Para obtener más ayuda, podemos escribir:
man ls | lesso en Git Bash:
ls --help | lessEsto también es útil cuando se enumeran archivos con muchos archivos. Podemos escribir:
ls -lart | less38.8.4 Comodines
Algunos de los aspectos más poderosos de Unix son los comodines (wild cards en inglés). Supongan que queremos eliminar todos los archivos HTML temporeros producidos durante la resolución de problemas para un proyecto. Imagínense que hay docenas de archivos. Tomaría muchísimo tiempo eliminarlos uno por uno. En Unix, podemos escribir una expresión que significa todos los archivos que terminan en .html. Para hacer esto, escribimos el comodín *. Como se discutió en la parte de wrangling de datos de este libro, este carácter significa cualquier número de cualquier combinación de caracteres. Específicamente, para enumerar todos los archivos HTML, escribimos:
ls *.htmlPara eliminar todos los archivos HTML en un directorio, escribimos:
rm *.htmlEl otro comodín útil es el símbolo ?. Esto significa cualquier carácter individual. Entonces, si todos los archivos que queremos borrar tienen la forma file-001.html con los números que van del 1 al 999, podemos escribir:
rm file-???.htmlEsto solo eliminará archivos con ese formato.
Además, podemos combinar comodines. Por ejemplo, para eliminar todos los archivos con el nombre file-001 independientemente del sufijo, podemos escribir:
rm file-001.*Advertencia: combinando rm con el comodín * puede ser peligroso. Hay combinaciones de estos comandos que borrarán todo sus sistemas de archivos sin preguntar “¿está seguro?”. Asegúrense de entender cómo funciona antes de usar este comodín con el comando rm.
38.8.5 Variables de entorno
Unix tiene configuraciones que afectan el entorno (environment en inglés) de sus líneas de comando. Estas se llaman variables de entorno. El directorio home es uno de ellos. De hecho, podemos cambiar algunos de estos. En Unix, las variables se distinguen de otras entidades agregando un $ en le comienzo. El directorio home se guarda en $ HOME.
Anteriormente vimos que echo es el comando Unix para imprimir. Entonces, podemos ver nuestro directorio home al escribir:
echo $HOMEPueden verlos todos al escribir:
envPueden cambiar algunas de estas variables del entorno. Pero sus nombres varían según los diferentes shells. Describimos los shells en la siguiente sección.
38.8.6 Shells
Mucho lo que usamos en este capítulo es parte de lo que se llama el Unix shell. Hay varios shells diferentes, aunque estas diferencias son casi imperceptibles. A la vez, son importantes, aunque no los cubrimos aquí. Pueden ver qué shell están utilizando escribiendo:
echo $SHELLEl más común es bash.
Una vez que sepan el shell que estan usando, pueden cambiar las variables de entorno. En Bash Shell, lo hacemos usando export variable value. Para cambiar la ruta, que se describirá con más detalle pronto, escriban: (Esto es solo un ejemplo. ¡Asegúrense de no ejecutar este comando!)
export PATH =/usr/bin/Hay un programa que se ejecuta cuando usan el terminal donde pueden editar variables para que cambien cada vez que usen el terminal. Esto cambia en diferentes implementaciones, pero si usan bash, pueden crear un archivo llamado .bashrc, .bash_profile,.bash_login o .profile. Es posible que ya tengan uno.
38.8.7 Ejecutables
En Unix, todos los programas son archivos. Se llaman ejecutables (executables en inglés). Entonces ls, mv y git son todos archivos. ¿Pero dónde están estos archivos de programas? Pueden averiguarlo usando el comando which:
which git
#> /usr/bin/gitEse directorio probablemente está lleno de archivos de programas. El directorio /usr/bin usualmente contiene muchos archivos de programa. Si escriben:
ls/usr/binen su terminal, verán varios archivos ejecutables.
Hay otros directorios que generalmente contienen archivos de programas. El directorio Application en la Mac o Program Files en Windows son ejemplos.
Cuando escriben ls, Unix sabe que debe correr un programa que es un ejecutable y que se almacena en algún otro directorio. Entonces, ¿cómo sabe Unix dónde encontrarlo? Esta información se incluye en la variable de entorno $PATH. Si escriben:
echo $PATHverán una lista de directorios separados por :. El directorio /usr/bin es probablemente uno de los primeros en la lista.
Unix busca archivos de programas en esos directorios en ese orden. Aunque no lo discutimos aquí, pueden crear ejecutables ustedes mismos. Sin embargo, si lo colocan en su directorio de trabajo y este directorio no está en la ruta, no pueden ejecutarlo simplemente escribiendo el comando. Se evita esto escribiendo la ruta completa. Entonces, si sus comandos se llama my-ls, pueden escribir:
./my-lsUna vez que hayan dominado los conceptos básicos de Unix, consideren aprender a escribir sus propios ejecutables, ya que pueden ayudar a reducir el trabajo repetitivo.
38.8.8 Permisos y tipos de archivo
Si escriben:
ls -lAl principio, verán una serie de símbolos como este -rw-r--r--. Esta cadena indica el tipo de archivo: archivo normal -, directorio d o ejecutable x. Esta cadena también indica el permiso del archivo: ¿Se puede leer? ¿Se puede cambiar? ¿Es ejecutable? ¿Otros usuarios del sistema pueden leer el archivo? ¿Otros usuarios pueden editar el archivo? ¿Otros usuarios pueden ejecutar si el archivo es ejecutable? Esto es más avanzado que lo que cubrimos aquí, pero pueden aprender mucho más en un libro de referencia de Unix.
38.8.9 Comandos que deben aprender
Hay muchos comandos que no discutimos en detalle en este libro, pero queremos darles un poco de información sobre ellos y lo que hacen. Son:
open/start - En la Mac,
open filenameintenta averiguar la aplicación correcta del nombre de archivo y abrirlo con esa aplicación. Este es un comando muy útil. En Git Bash, pueden tratarstart filename. Intenten abrir un archivoRoRmdconopenostart: deberían abrirlo con RStudio.nano: Un editor de texto básico.
ln: Crea un enlace simbólico. No recomendamos su uso, pero deben estar familiarizados con él.
tar: Archiva archivos y subdirectorios de un directorio en un solo archivo.
ssh: Se conecta a otra computadora.
grep: Busca patrones en un archivo.
awk/sed: Estos son dos comandos muy útiles que les permite encontrar cadenas específicas en archivos y cambiarlas.
38.8.10 Manipulación de archivos en R
También podemos realizar el manejo de archivos desde R. Las funciones claves para aprender se pueden ver mirando el archivo de ayuda para
?files. Otra función útil es unlink.
Aunque generalmente no lo recomendamos, tengan en cuenta que pueden ejecutar comandos de Unix en R usando system.
https://www.quora.com/Which-are-the-best-Unix-Linux-reference-books↩︎
https://jvns.ca/blog/2018/08/05/new-zine--bite-size-command-line/↩︎
https://library.si.edu/sites/default/files/tutorial/pdf/filenamingorganizing20180227.pdf↩︎
https://rafalab.github.io/dsbook/accessing-the-terminal-and-installing-git.html↩︎